Transformer는 Inductive Bias이 부족하다라는 의미는 무엇일까?
Inductive Bias가 딥러닝 알고리즘에 미치는 영향은 무엇일까……?
moon-walker.medium.com
위의 글에서 중요한 부분
Q: What is inductive bias in machine learning? Why is it necessary?
A1. Every machine learning algorithm with any ability to generalize beyond the training data that it sees has some type of inductive bias, which are the assumptions made by the model to learn the target function and to generalize beyond training data. For example, in linear regression, the model assumes that the output or dependent variable is related to independent variable linearly (in the weights). This is an inductive bias of the model.
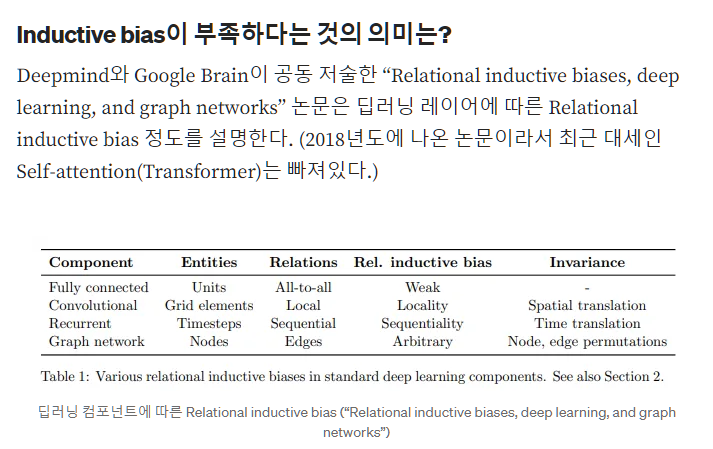
일반적으로 머신러닝 모델은 특정 데이터셋에 대해 더 좋은 성능을 얻고자 Inductive bias를 의도적으로 강제해준다. 예를들어 Vision 정보는 인접 픽셀간의 locality가 존재한다는 것을 미리 알고 있기 때문에 Conv는 인접 픽셀간의 정보를 추출하기 위한 목적으로 설계되어 Conv의 inductive bias가 local 영역에서 spatial 정보를 잘 뽑아낸다. RNN은 순차적인(Sequential) 정보를 잘 처리하기 위해 설계되었다. 반면 Fully connected(MLP)는 all(input)-to-all (output) 관계로 모든 weight가 독립적이며 공유되지 않아 inductive bias가 매우 약하다. Transformer는 attention을 통해 입력 데이터의 모든 요소간의 관계를 계산하므로 CNN보다는 Inductive Bias가 작다라고 할 수 있다. 따라서 Inductive Bias의 순서는 CNN > Transformer > Fully Connected 라고 예상할 수 있다.
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net
* 밑의 글은 모두 위의 글에서 복사 붙여넣기 한 것이다.
버트는 구글이 공개한 pre-trained model이다.
트랜스포머 인코더 층의 수를 L, d_model의 크기를 D, 셀프 어텐션 헤드의 수를 A라고 하였을 때 각각의 크기는 다음과 같습니다.
BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
그렇다면 BERT는 어떻게 모든 단어들을 참고하여 문맥을 반영한 출력 임베딩을 얻게 되는 것일까요? 사실 이에 대한 해답을 여러분은 이미 알고있는데, 바로 '셀프 어텐션'입니다. BERT는 기본적으로 트랜스포머 인코더를 12번 쌓은 것이므로 내부적으로 각 층마다 멀티 헤드 셀프 어텐션과 포지션 와이즈 피드 포워드 신경망을 수행하고 있습니다.
BERT가 사용한 토크나이저는 WordPiece 토크나이저로 서브워드 토크나이저 챕터에서 공부한 바이트 페어 인코딩(Byte Pair Encoding, BPE)의 유사 알고리즘입니다. 동작 방식은 BPE와 조금 다르지만, 글자로부터 서브워드들을 병합해가는 방식으로 최종 단어 집합(Vocabulary)을 만드는 것은 BPE와 유사합니다.
포지션 임베딩 :
트랜스포머에서는 포지셔널 인코딩(Positional Encoding)이라는 방법을 통해서 단어의 위치 정보를 표현했습니다. 포지셔널 인코딩은 사인 함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법입니다. BERT에서는 이와 유사하지만, 위치 정보를 사인 함수와 코사인 함수로 만드는 것이 아닌 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용합니다.
1) 마스크드 언어 모델(Masked Language Model, MLM)
BERT는 사전 훈련을 위해서 인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 마스킹(Masking)합니다. 그리고 인공 신경망에게 이 가려진 단어들을(Masked words) 예측하도록 합니다. 중간에 단어들에 구멍을 뚫어놓고, 구멍에 들어갈 단어들을 예측하게 하는 식입니다. 예를 들어 '나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다'를 주고 '슈퍼'와 '우유'를 맞추게 합니다.

- 회고:
- 4강 듣는 중인데 모르는 게 있을 때마다 위에서처럼 자꾸 길을 샌다.
'AI' 카테고리의 다른 글
| Feature Enigneering 공부 (0) | 2024.01.12 |
|---|---|
| GLORY 리뷰 (0) | 2024.01.09 |
| 8주차 회고 (0) | 2023.12.29 |
| 5,6주차 회고 (0) | 2023.12.16 |
| EDA 가 무엇인가 (0) | 2023.12.14 |

