1. Introduction
SVD란? Singular vector decomposition, 특이값 분해 : 행렬 분해
𝑀ˆ = 𝑈 Σ𝑉* 으로 분해한 뒤 M으로 ∥𝑀 − 𝑀ˆ ∥^2 작아지도록 근사함

truncated SVD란 ? ∑의 대각 원소 중 상위 t개만 추출
추천시스템에서 유저-아이템 매트릭스를 truncated SVD로 저차원 분해하여 유저, 아이템 임베딩을 얻기 위해 사용
* M^의 rank는 f , f << min(n,m), The f largest singular values and eigenvetors of M 을 얻는다
* The close-form solution to the SVD is such that 𝑈 is the 𝑓 dominant eigenvectors of 𝑀𝑀∗ to retrieve U. (V는 무시됨)
Spikes : 임베딩 벡터가 직선을 따라 스스로 모이는 경향을 보임
(embedding vectors tend to self-organize along lines that pass through the origin)
- goes unnoticed when using the cosine distance for similiarity , since the normalization squashes all points on a hypersphere
- normalization을 안했기 때문에 norm이 살아있고, norm of the vectors may be more insightful
- Spikes are prevalent in music dataset !!
- 논문이 spikes가 communities를 상징한다는 것을 의미하고, embedding's norms가 벡터가 속한 community의 varying importance를 나타낸다는 것을 증명하였다.
-> In detail, we prove that spikes represent communities, and embeddings’ norms stem from their varying importance within that community (i.e., intra-popularity)
의의 :
1. first propse a unified metric to quantify this spiking effect
2. mathematically prove the equivalence of spiking geometry with the presence of communities and intra-popularity within each community
2. metric Spk
- 전제: embeddings with the highest norms -> candidate peaks for spikes
- 실험: lower norm가진 points들이 highest norm(candidate)에 collinear한지 측정함. ( threshold를 사용함 : 𝜃 and 𝜌)
=> if cos(𝑒 ∗ , 𝑒) > cos(𝜃) any other vector 𝑒 belongs to the spike( 𝑒 ∗ ) 라고 정의
- We iterate for candidate peaks 𝑒 ∗ in descending order of norm until we have captured a ratio 𝜌 of points in the distribution (비교하는 lower norm의 비율에 제한을 둠)
- spikes의 개수를 세어준 뒤 n - total number of embeddings으로 나눠준다
그러면, 0<Spk<= 𝜌 : 0에 가까울 수록 하나의 spike에 모인거고, 상한이면 어떠한 두 점도 collinear하지 않다는 것을 의미함.
===> spike 현상을 spectral clustering , presence of structured groups in the data로 해석함.
3. modeling
목표 : the spiking structure in the SVD-embedding space 와 presence of communities of varying node degrees in the graph associated with M^ 는 동치(equivalence)임을 증명한다.
Community graph models : The stochastic Block Model(SBM) generate random graphs according to an underlying structure in communities.
DCBM- Degree corrected SBM - 추가적으로 commuity 내에서 edge probability를 나타내는 파라미터 (𝛼𝑖) ∈ [0, 1] 를 추가
(intra popularity를 의미하는 것 같음 , varying importance of edges)


Interpretation :
- sub-matrix 𝑀ˆ follows a structure in communities given by a DCBM
- DCBM is merely a matrix with constant blocks that is multiplied element-wise by the rank-1 matrix [𝛼1, ...𝛼𝑛 ′ ] ∗ [𝛼1, ...𝛼𝑛 ′ ].
=> minimize ∥𝑀 − 𝑀ˆ ∥^2 로 최적화할 때 rebuilding as many communities as possible with rank-1 matrices is intuitively more optimal 할 수 있게 튜닝해야 한다. (higher rank matrix 로 single community에 속하는 eigenvectors로 fine-tune하는 것보다)
low rank -> lower dimension -> spikies 개수 증가 -> community 개수 증가
higher rank -> higher dimension -> spikes 개수 감소 -> community 개수 감소
=> optimization할 때 f의 차원을 튜닝해야함
3.3 Practical advice
spike formations with DCBM communities은추천을 위한 유용한 특징을 가진다
1. Fast Degree Estimatioin
-그래프를 그리지 않고 the degree of a node of the denoised matrix 𝑀ˆ 를 알 수 있는 것은 매우 큰 장점이다.
예를 들면, the topology of a graph may be estimated from its degree distribution (e.g., whether the graph is scale-free), which has been suggested to be indicative of a rather social or information nature of the music graphs [5]. Degree centrality has also been related to popularity biases in music data [8, 44] or used to create hierarchies [1]. More generally, the degree of a node is a strong predictor of its robustness to change in a graph.
* degree of node : 노드의 이웃 수
* degree centrality : 노드가 그래프에서 얼마나 중요한가 ->https://process-mining.tistory.com/151
2. Cosine similarity or dot product?
SVD를 사용할 때 둘 중에 어떤 것을 선택할지에 대해 추가적인 정보로 도움을 줌.
- DCBM에서 degree heterogenieity의 효과를 방지할 때 spherical clustering을 사용하는데 이것은 cosine similiarity를 사용하는 것과 같다.
- Cosine similiarity : community들을 살펴 볼 수 있어 그 community를 가장 잘 대표하는 물건을 선택하는 데 유용하다.
more suited for artist similarity and cold-start applications.
- dot product : suited to propose a panopticon view of the many available items, but risk of being baised by popularity (long-tail problem)
3. Tuning of 𝑓 . : f는 truncation parameter로써 튜닝을 잘해서 clean communities를 capture할 수 있게 해야 한다는 조언.
4. OPENING : INDUSTRIAL USE-CASE
실무에서 추천시스템는 무겁고 복잡한 모델을 돌리기 어려움. SVD같은 간단한 모델의 파이프라인을 유지한채로 spike로부터 추가 지식을 얻을 수 있다.
특히, 음악 데이터는 community effects를 보이기 쉽다.
higher norm -> 변화에 높은 robustesness -> better stability in time
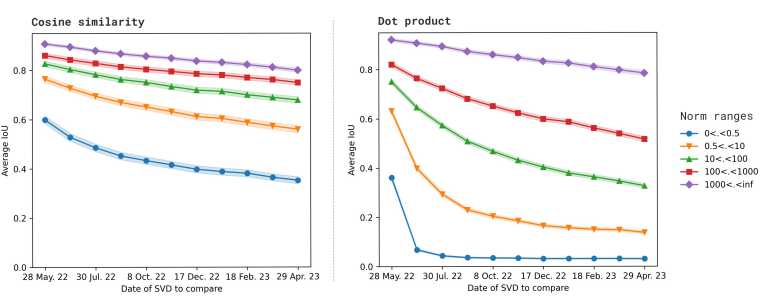
norm에 따라 5개의 임베딩 그룹으로 분리하고, SVD를 계산
mean Jaccard index (IoU) to quantify the relative similarity between the top items of the reference and subsequent compared date.
where low-norm embeddings quickly become irrelevant while higher-norm ones remain over 80% similar after almost a year. -> we could expect well-established music genres to remain stable (e.g. jazz music tracks)
'AI' 카테고리의 다른 글
| GPT4Rec 리뷰 (0) | 2024.01.31 |
|---|---|
| Rethinking Personalized Ranking at Pinterest: An End-to-EndApproach 리뷰 (0) | 2024.01.23 |
| 대략 01/12의 공부 일지 + 10주차 회고 (0) | 2024.01.12 |
| Feature Enigneering 공부 (0) | 2024.01.12 |
| GLORY 리뷰 (0) | 2024.01.09 |



